Dunja Radulov
wrote this on
January 24, 2017
The end of each year is a time to make plans for the following year and get
inspired to work on new and exciting things in the year ahead. In December, we
decided to organize a Semaphore hackathon
for the entire company to celebrate the end of 2016 by getting creative.
People pitched their ideas and others voted with their feet by joining
the projects they were most interested in. We split into multidisciplinary
teams that had three days to capture new ideas and have fun making them
a reality. Keep reading to find out what are the projects we came up with,
what we learned working on them, and what are some of the outcomes of our
first internal hackathon.

Improving the Semaphore SSH session
Team members: Ervin, Igor, Marko, Milan, Milica and Sneha
The Semaphore SSH session proved to be a popular asset for debugging builds and
deployments. From the start, there were things we wanted to improve, but
the team was short on time, and these changes weren’t very high on our list of
priorities, so our team decided to work on some improvements during the
hackathon.
The most obvious thing we wanted to improve was the lack of contextual
information, e.g. the build which is currently checked out in the session and
time until completion. We decided to add a few extra touches which would provide
this information right off the bat. Another pain point we wanted to address is
copy-pasting the build commands into the SSH environment. The utility
addressing this shortcoming is soon to be released.
We played around with a few other ideas which didn’t see the daylight, but the
hackathon was a great team effort and bonding experience for everyone in the
team.
Finding trends in support request messages
Team members: Milana, Marija, Filip, Nemanja and Jovan
Our team was interested in finding trends in support request messages sent by
our users. For this purpose, we collected a set of our messages from Intercom,
and applied various machine learning techniques to it.
We spent our hackathon time playing around with the messages, clustering them
based on topic using different algorithms and trying out sentiment analysis on
them. We mostly relied on Python and its rich machine learning libraries as our
tools.
After three days, we ended up with a prototype which tracks the rate of
occurrence of current topics and visualizes this with Kibana.
The hackathon provided us with a wonderful opportunity to step outside of our
everyday tasks and tools and develop ideas that otherwise might not have been
considered worth our time. Combining this with a mini-vacation-like
atmosphere, the entire event proved to be refreshing, fun, and a great prelude
to the upcoming holiday season.
Making the TV great again
Team members: Marko, Nemanja, Nikola, Stefan and Misel
Our team looked around the office and asked ourselves, what is there that we can improve
and make great again? As it often turns out, you don’t need to look far. There
was a spare TV sitting turned off in the office lobby, so we decided to make it
show a dashboard that would be fun and useful for everyone.
The Semaphore TV now shows things like a photo from the place our latest
customer hails from, recent tweets to @semaphoreci,
and a world map of recently active users. Best of all, it plays a different
music theme every time we get a new customer.
On the tech side, we played with serverless architecture and implemented the
dashboard and all supporting endpoints as microservices running on AWS Lambda.
Recent support for running Express.js apps on Lambda has been very useful.
Overall, it was a really fun experience!
Improving employee experience
Team members: Katarina, Milica, Filip and Marija
Our team had many ideas simming in their heads on what would help improve our
employee experience, so we decided to work on two different projects.
We wanted to explore different employee engagement tools for a
while now, so the hackathon presented the right opportunity to do so.
For the first project, we created a new Slack channel named ‘Humans and Bots’,
and picked three tools seemed most promising. We decided to test
drive Leo from the Office Vibe, Polly chat bot and Captain Feedback. Each tool
has different merits. We found the Polly to be the most engaging one.
Polly is currently a free tool, and it’s easy to use straight from the start.
It has predefined questions on ‘Team Happiness’, and you can choose the
frequency of questions asked, as well as set your answers to be completely
anonymous if you wish so.
The second project was to create a simple static site for our internal use with
interesting links for the team and a Google form questionnaire on team
happiness. This was a fun project to do, and it included some coding. The content
included were useful slideshares, interesting books to read, and links to events
to attend. All in all, the hackathon was a great learning experience and
a nice opportunity for teamwork.
The path to TDD enlightenment
Team members: Nemanja, Tamara, Milica and Dunja
Since we had a multidisciplinary team including a developer, a designer and two
marketers/editors/writers, we decided to use our combined skills to create an
interactive experience (i.e. a game) that plays with the pitfalls of software
development and the true path of TDD.
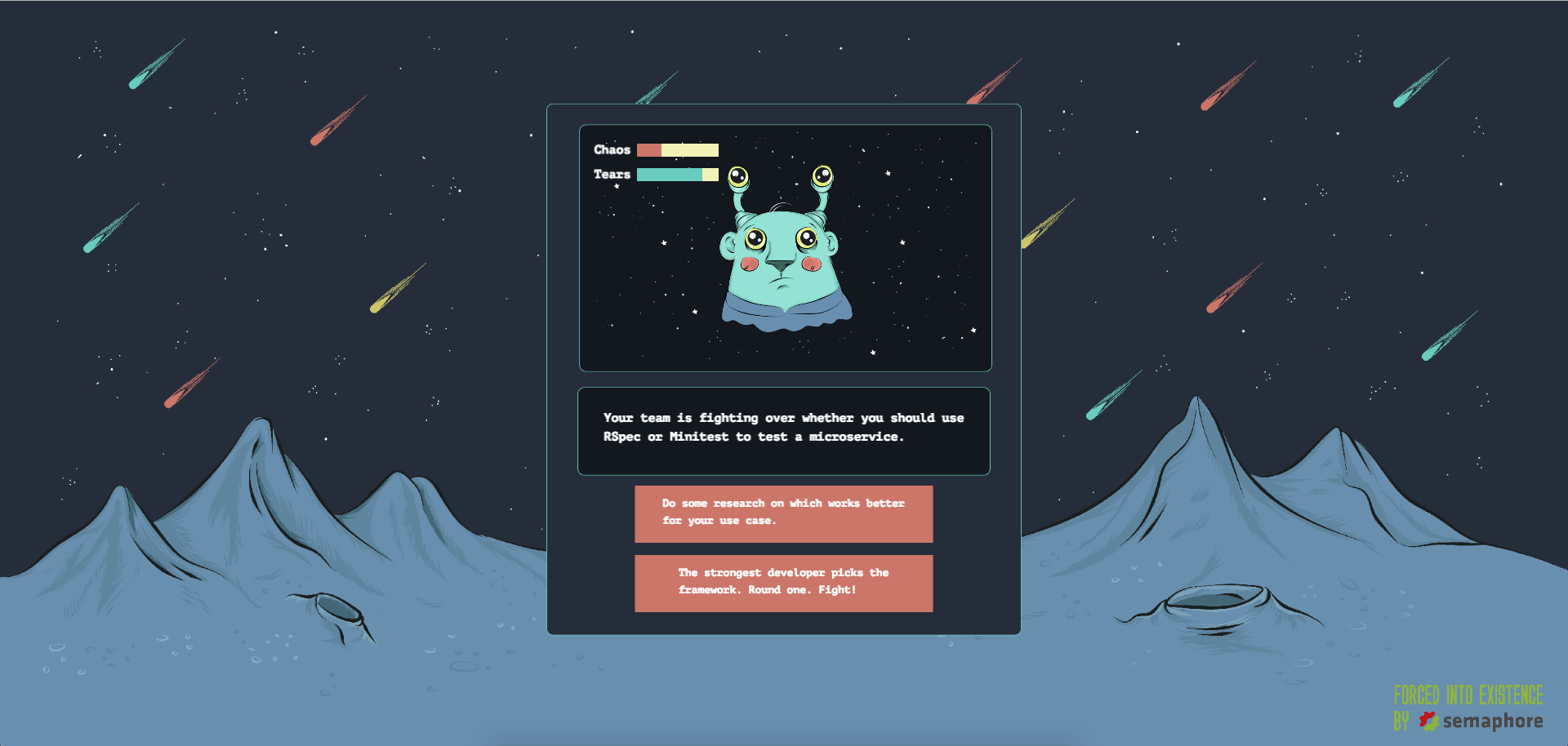
The game puts the player in the shoes of a developer chosen to lead a team
cleaning up a tricky project, an app left behind by a developer that’s rumoured to have
gone insane. The code is complex, unreadable and ridden with bugs, and the
deadline is tight, so the player needs to use TDD and common sense in order to
manage the chaos without spilling too many tears. Working on the game helped us
remember and better understand why testing and TDD matter, and allowed us to
get creative and have fun together as a team.
All in all, the hackathon was a fun experience during which we played with some
new ideas, bonded as a team, and got energized for a creative and fun year ahead
of us.





